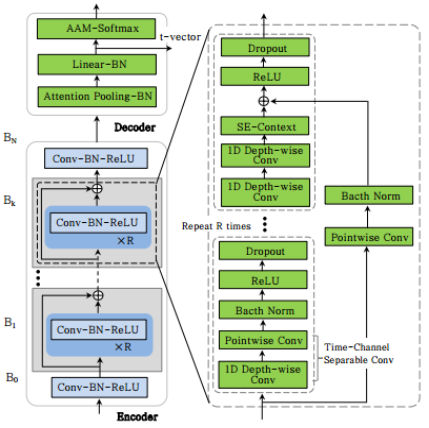
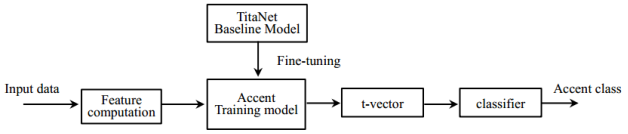
In this paper, we introduce a spoken accent identification system for the Korean language, which utilize t-vector embeddings extracted from state-of-the-art TitaNet neural network. To implement the Korean spoken accent identification system, we propose two approaches: First, we introduce a collection method of training data for the Korean spoken accent identification. Korean accents can be broadly classified into four categories: standard accent, southern accent, northwestern accent and northeastern accent. Generally, in Korean language, the speech data for standard accent can be easily obtained via different videos and websites, but the rest of the data except standard accent are very rare and therefore difficult to collect. To mitigate the impact of this data scarcity, we introduce a synthetic audio augmentation using Text-to-Speech (TTS) synthesis techniques. This process is done under the condition that the synthetic audio generated by TTS should be retain accent information of original speaker. Second, we propose an approach to build the deep neural network (DNN) for Korean spoken accent identification in a manner that fine-tune the trainable parameters of a pre-trained TitaNet speaker recognition model by using aforementioned training dataset. Based on the trained TitaNet model, the accent identification is performed using t-vector embedding features extracted from that model, and cosine distance function. The experimental results show that our proposed accent identification system is superior to the systems based on other state-of-the-art DNNs such as the x-vector and ECAPA-TDNN.
| Published in | Science Research (Volume 13, Issue 2) |
| DOI | 10.11648/j.sr.20251302.11 |
| Page(s) | 13-20 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
Spoken Accent Identification, T-vector, Deep Neural Network, Fine-tuning, Synthetic Audio Augmentation (SSA), Titanet, 1D time -channel Separable Convolution, Squeeze and-Excitation (SE)
Accent | Segment Number | Speaker Number | Min length (s) | Max length (s) | Avg length (s) | Total (hrs) |
|---|---|---|---|---|---|---|
Normal | 17372 | 104 | 2.5 | 18.5 | 9.6 | 48.2 |
Southern | 2720 | 17 | 2.6 | 14.3 | 8.6 | 6.5 |
Northwest | 4018 | 28 | 2.2 | 12.6 | 10.2 | 11.4 |
Northeast | 1838 | 13 | 3.4 | 12.8 | 9.4 | 4.8 |
Total | 25948 | 162 | 2.7 | 14.5 | 9.5 | 70.9 |
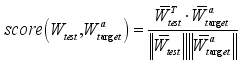 (1)
(1) 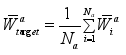 (3)
(3) 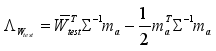 (4)
(4) 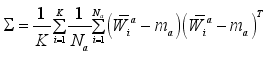 (5)
(5) 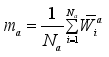 (6)
(6) Model | Number of model parameters (M) | EERavg (%) |
|---|---|---|
x-Vector [5] | 4.6 | 4.54 |
ECAPA-TDNN [ 16] | 6.2 | 1.16 |
TitaNet-S [20] | 6.4 | 0.93 |
Accent | EER (%) |
|---|---|
Standard | 0.43 |
Southern | 0.75 |
Northwest | 1.62 |
Northeast | 0.94 |
Accent | Classifier Scoring | |
|---|---|---|
Cosine Scoring | Gaussian Scoring | |
Standard | 0.43 | 0.45 |
Southern | 0.75 | 0.83 |
Northwest | 1.62 | 1.69 |
Northeast | 0.94 | 1.12 |
Actual | |||||
|---|---|---|---|---|---|
Standard | Southern | Northwest | Northeast | ||
Pred icted | Standard | 99.2 | 0.1 | 0.5 | 0.1 |
Southern | 0.4 | 98.8 | 0.7 | 0.2 | |
Northwest | 1.3 | 0.7 | 97.8 | 0.1 | |
Northeast | 0.8 | 0.3 | 0.5 | 98.3 | |
DNN | Deep Neural Network |
SAA | Synthetic Audio Augmentation |
TTS | Text To Speech |
VAD | Voice Activation Detection |
ASR | Automatic Speech Recognition |
SE | Squeeze and-Excitation |
LR | Learning Rate |
EER | Equal Error Rate |
| [1] | H. Behravan, V. Hautamaki et al., “Factors affecting i-vector based foreign accent recognition: A case study in spoken Finnish,” Speech Communication, vol. 19, pp. 118-129, 2015. |
| [2] | Sreedhar Potla, Vishnu Vardhan. B, “Spoken Language Identification using Gaussian Mixture Model-Universal Background Model in Indian Context,” International Journal of Applied Engineering Research, vol. 13, no. 5, pp. 2694-2700, 2018. |
| [3] | N. Dehak, P. J. Kenny, R. Dehak, P. Dumouchel, and P. Ouellet,“Front-end factor analysis for speaker verification,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 4, pp. 788–798, 2011. |
| [4] | N. Dehak, P. A. Torres-Carrasquillo, D. Reynolds, R. Dehak, “Language Recognition via Ivectors and Dimensionality Reduction,” INTERSPEECH, 2011, pp. 857–860. |
| [5] | D. Snyder, D. Garcia-Romero, A. McCree, G. Sell, D. Povey, and S. Khudanpur, “Spoken Language Recognition using Xvectors,” pages 105–111, June 2018a. |
| [6] | He, K., Zhang, X., Ren, S. & Sun, J. (2016), Deep residual learning for image recognition, in ‘Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR)’, pp. 770–778. |
| [7] | Katta, S. V., Umesh, S. et al. (2020), ‘S-vectors: Speaker embeddings based on transformer’s encoder for text-independent speaker verification’, arXiv preprint arXiv: 2008.04659 |
| [8] | Behravan, H., Hautama ¨ki, V., Kinnunen, T., 2013. Foreign accent detection from spoken Finnish using i-Vectors. In: INTERSPEECH 2013: 14th Annual Conference of the International Speech Communication Association, Lyon, France, August 25–29, pp. 79–83. |
| [9] | S. Soonshin et al., “Self-Attentive Multi-Layer Aggregation with Feature Recalibration and Deep Length Normalization for Text-Independent Speaker Verification System”, Electronics 2020, 9, 1706; |
| [10] | M. Rouvier et al, “Review of different robust x-vector extractors for speaker verification,” EUSIPCO 2020, pp. 366-370 |
| [11] | D. Povey, G. Cheng, Y. Wang, et al., “Semi-Orthogonal Low-Rank Matrix Factorization for Deep Neural Networks,” in Proceedings of the 19th Annual Conference of the International Speech Communication Association, INTERSPEECH 2018, Hyderabad, India, sep 2018. |
| [12] | Wang, Q., Okabe, K., Lee, K. A., Yamamoto, H. & Koshinaka, T. (2018), Attention mechanism in speaker recognition: What does it learn in deep speaker embedding?, in ‘2018 IEEE Spoken Language Technology Workshop (SLT)’, IEEE, pp. 1052–1059. |
| [13] | Yanpei Shi, “Improving the Robustness of Speaker Recognition in Noise and Multi-Speaker Conditions Using Deep Neural Networks,” PhD Thesis, Department of Computer Science, University of Sheffield, 2021. |
| [14] | Ville Vestman, Kong Aik Lee, Tomi H. Kinnunen, “Neural i-vectors”, Odyssey 2020 The Speaker and Language Recognition Workshop, 2020, pp 67–74. |
| [15] | India Massana, M. A., Safari, P. & Hernando Peric´as, F. J. (2019), Self multi-head attention for speaker recognition, in ‘Interspeech 2019: the 20th Annual Conference of the International Speech Communication Association: 15-19 September 2019: Graz, Austria’, International Speech Communication Association (ISCA), pp. 4305–4309. |
| [16] | B. Desplanques, et al., “Ecapa-tdnn: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification,” arXiv preprint arXiv: 2005.07143, 2020. |
| [17] | Hengyi Zou, Sayaka Shiota, “Vocal Tract Length Perturbation-based Pseudo-Speaker Augmentation Considering Speaker Variability for Speaker Verification,” Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 2024. |
| [18] | Vishwas M. Shetty et al., “ENHANCING AGE-RELATED ROBUSTNESS IN CHILDREN SPEAKER VERIFICATION,” arXiv: 2502.10511v1 [eess. AS] 14 Feb 2025. |
| [19] | Li Zhang et al., “Adaptive Data Augmentation with NaturalSpeech3 for Far-field Speaker Verification,” arXiv: 2501.08691v1 [cs. SD] 15 Jan 2025 |
| [20] | N. R. Koluguri, T. Park, and B. Ginsburg, “Titanet: Neural model for speaker representation with 1d depth-wise separable convolutions and global context,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 8102–8106. |
| [21] | Ahmad Iqbal Abdurrahman, Amalia Zahra, “Spoken language identification using i-vectors, x-vectors, PLDA and logistic regression”, Bulletin of Electrical Engineering and Informatics Vol. 10, No. 4, August 2021, pp. 2237~2244 |
| [22] | S. K. Gupta, S. Hiray, P. Kukde, “Spoken Language Identification System for English-Mandarin Code-Switching Child-Directed Speech”, INTERSPEECH 2023, pp. 4114~4118 |
| [23] | Alec Radford et al., “Robust speech recognition via largescale weak supervision,” in International Conference on Machine Learning. PMLR, 2023, pp. 28492–28518. |
| [24] | Alexei Baevski et al., “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Ad vances in neural information processing systems, vol. 33, pp. 12449–12460, 2020. |
| [25] | Amrutha Prasad et al., FINE-TUNING SELF-SUPERVISED MODELS FOR LANGUAGE IDENTIFICATION USING ORTHONORMAL CONSTRAINT,” IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 11921-11925. |
| [26] | Vadim Popov et al., “Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech,” arXiv: 2105.06337v2 [cs. LG] 5 Aug 2021 |
| [27] | Kong, J. et al., “HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis,” In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, virtual, 2020. |
| [28] | W. Han, Z. Zhang, Y. Zhang, et al., “ContextNet: Improving convolutional neural networks for automatic speech recognition with global context,” arXiv: 2005.03191, 2020. |
| [29] | Kriman, S. et al., “Quartznet: Deep Automatic Speech Recognition with 1D Time-Channel Separable Convolutions,” ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, 2020, pp. 6124–6128, |
| [30] | O. Kuchaiev, J. Li, H. Nguyen, O. Hrinchuk, R. Leary, B. Ginsburg, S. Kriman, S. Beliaev, V. Lavrukhin, J. Cook, et al., “Nemo: a toolkit for building ai applications using neural modules,” arXiv: 1909.09577, 2019. |
| [31] | S. Chen et al., “Wavlm: Large-scale selfsupervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022. |
| [32] | S. Ramoji, S. Ganapathy, “Supervised I-vector Modeling for Language and Accent Recognition,” Computer Speech & Language (2019). |
| [33] | Arun Babu et al., “XLS-R: Self-supervised cross-lingual speech representation learning at scale,” in Proc. Of Interspeech, 2022, pp. 2278–2282. |
APA Style
Om, Y. S., Kim, H. S. (2025). Korean Spoken Accent Identification Using T-vector Embeddings. Science Research, 13(2), 13-20. https://doi.org/10.11648/j.sr.20251302.11
ACS Style
Om, Y. S.; Kim, H. S. Korean Spoken Accent Identification Using T-vector Embeddings. Sci. Res. 2025, 13(2), 13-20. doi: 10.11648/j.sr.20251302.11
@article{10.11648/j.sr.20251302.11,
author = {Yong Su Om and Hak Sung Kim},
title = {Korean Spoken Accent Identification Using T-vector Embeddings
},
journal = {Science Research},
volume = {13},
number = {2},
pages = {13-20},
doi = {10.11648/j.sr.20251302.11},
url = {https://doi.org/10.11648/j.sr.20251302.11},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.sr.20251302.11},
abstract = {In this paper, we introduce a spoken accent identification system for the Korean language, which utilize t-vector embeddings extracted from state-of-the-art TitaNet neural network. To implement the Korean spoken accent identification system, we propose two approaches: First, we introduce a collection method of training data for the Korean spoken accent identification. Korean accents can be broadly classified into four categories: standard accent, southern accent, northwestern accent and northeastern accent. Generally, in Korean language, the speech data for standard accent can be easily obtained via different videos and websites, but the rest of the data except standard accent are very rare and therefore difficult to collect. To mitigate the impact of this data scarcity, we introduce a synthetic audio augmentation using Text-to-Speech (TTS) synthesis techniques. This process is done under the condition that the synthetic audio generated by TTS should be retain accent information of original speaker. Second, we propose an approach to build the deep neural network (DNN) for Korean spoken accent identification in a manner that fine-tune the trainable parameters of a pre-trained TitaNet speaker recognition model by using aforementioned training dataset. Based on the trained TitaNet model, the accent identification is performed using t-vector embedding features extracted from that model, and cosine distance function. The experimental results show that our proposed accent identification system is superior to the systems based on other state-of-the-art DNNs such as the x-vector and ECAPA-TDNN.
},
year = {2025}
}
TY - JOUR T1 - Korean Spoken Accent Identification Using T-vector Embeddings AU - Yong Su Om AU - Hak Sung Kim Y1 - 2025/06/30 PY - 2025 N1 - https://doi.org/10.11648/j.sr.20251302.11 DO - 10.11648/j.sr.20251302.11 T2 - Science Research JF - Science Research JO - Science Research SP - 13 EP - 20 PB - Science Publishing Group SN - 2329-0927 UR - https://doi.org/10.11648/j.sr.20251302.11 AB - In this paper, we introduce a spoken accent identification system for the Korean language, which utilize t-vector embeddings extracted from state-of-the-art TitaNet neural network. To implement the Korean spoken accent identification system, we propose two approaches: First, we introduce a collection method of training data for the Korean spoken accent identification. Korean accents can be broadly classified into four categories: standard accent, southern accent, northwestern accent and northeastern accent. Generally, in Korean language, the speech data for standard accent can be easily obtained via different videos and websites, but the rest of the data except standard accent are very rare and therefore difficult to collect. To mitigate the impact of this data scarcity, we introduce a synthetic audio augmentation using Text-to-Speech (TTS) synthesis techniques. This process is done under the condition that the synthetic audio generated by TTS should be retain accent information of original speaker. Second, we propose an approach to build the deep neural network (DNN) for Korean spoken accent identification in a manner that fine-tune the trainable parameters of a pre-trained TitaNet speaker recognition model by using aforementioned training dataset. Based on the trained TitaNet model, the accent identification is performed using t-vector embedding features extracted from that model, and cosine distance function. The experimental results show that our proposed accent identification system is superior to the systems based on other state-of-the-art DNNs such as the x-vector and ECAPA-TDNN. VL - 13 IS - 2 ER -
Institute of AI Technology, University of Science, Pyongyang, Democratic People’s Republic of Korea
Information