-

Non-parametric Variance Estimation Using Donor Imputation Method
Hellen W. Waititu,
Edward Njenga
Issue:
Volume 5, Issue 5, September 2016
Pages:
252-259
Received:
1 July 2016
Accepted:
16 July 2016
Published:
3 August 2016
Abstract: The main objective of this study is to investigate the relative performance of donor imputation method in situations that are likely to occur in practice and to carry out numerical comparative study of estimators of variance using Nadaraya-Watson kernel estimators and other estimators. Nadaraya-Watson kernel estimator can be viewed as a non-parametric imputation method as it leads to an imputed estimator with negligible bias without requiring the specification of a parametric imputation model. Simulation studies were carried out to investigate the performance of Nadaraya-Watson kernel estimators in terms of variance. From the results, it was found out that Nadaraya-Watson kernel estimator has negligible bias and its variance is small. When compared with Naïve, Jackknife and Bootstrap estimators, Nadaraya-Watson kernel estimator was found to perform better than bootstrap estimator in linear and non-linear populations.
Abstract: The main objective of this study is to investigate the relative performance of donor imputation method in situations that are likely to occur in practice and to carry out numerical comparative study of estimators of variance using Nadaraya-Watson kernel estimators and other estimators. Nadaraya-Watson kernel estimator can be viewed as a non-paramet...
Show More
-
Application of Loess Procedure in Modelling Geothermal Well Discharge Data from Menengai Geothermal Wells in Kenya
Madegwa James Etyang,
Edward Gachangi Njenga
Issue:
Volume 5, Issue 5, September 2016
Pages:
260-269
Received:
15 July 2016
Accepted:
22 July 2016
Published:
6 August 2016
Abstract: To measure the output of a geothermal well, also known as amount of megawatts of a well, discharge tests are done between two to four months after drilling of the well to collect the relevant types of data which includes wellhead pressure, lip pressure and the weir height. After collection of these data, [8] formula is applied in determining the well output. These data exhibits skewness and excess kurtosis also known as heavy – tailedness, an attempt to fit ordinary least squares (OLS) model to such data leads to model misspecification. Therefore, in this study, robust non-parametric estimation has been used to fit these data as applied by [1]. The model is known to be robust to outliers which characterize the wells data, robustness signifies insensitivity to deviations from the strict model assumptions. A comparison between the robust method used and OLS method has also been made with graphical illustrations. The results show that locally weighted regression (loess) method used with a smoothing parameter of 0.07 and a polynomial of order 2 fits the geothermal well discharge data. It was confirmed that geothermal well discharge data is characterized by outliers which may affect the ultimate determination of the value of a well output and therefore there is need for further statistical data processing to remove the errors before Russel James method is applied.
Abstract: To measure the output of a geothermal well, also known as amount of megawatts of a well, discharge tests are done between two to four months after drilling of the well to collect the relevant types of data which includes wellhead pressure, lip pressure and the weir height. After collection of these data, [8] formula is applied in determining the we...
Show More
-
Intrinsically Ties Adjusted Partial Tau (C-Tap) Correlation Coefficient
Oyeka Ikewelugo Cyprian Anaene,
Osuji George Amaeze,
Obiora-Ilouno Happiness Onyebuchi
Issue:
Volume 5, Issue 5, September 2016
Pages:
270-279
Received:
21 December 2015
Accepted:
24 May 2016
Published:
10 August 2016
Abstract: This paper present a non-parametric statistical method for the estimation of partial correlation coefficient intrinsically adjusted for tied observations in the data. The method based on a modification of the method of estimating Tau correlation coefficient may be used when the population of interest are measurements on as low as the ordinal scale that are not necessary continuous or even numeric. The estimated partial correlation coefficient is a weighted average of the estimates obtained when each of the observations whose assigned ranks are arranged in their natural order as well as the observations whose assigned ranks are tagged along, with the weights being functions of the number of tied observations in each population. It is shown that failure to adjust for ties tends to lead to an underestimation of the true partial correlation coefficient, an effect that increases with the number of ties in the data. The proposed method is illustrated with some data and shown to compare favorably with the Kendall approach.
Abstract: This paper present a non-parametric statistical method for the estimation of partial correlation coefficient intrinsically adjusted for tied observations in the data. The method based on a modification of the method of estimating Tau correlation coefficient may be used when the population of interest are measurements on as low as the ordinal scale ...
Show More
-
On Properties of the Inverse Cube Transformation of Error Component of the Multiplicative Time Series Model
Dike A. O.,
Otuonye E. L.,
Chikezie D. C.,
Sambo D.
Issue:
Volume 5, Issue 5, September 2016
Pages:
280-284
Received:
19 May 2016
Accepted:
1 July 2016
Published:
17 August 2016
Abstract: This paper examines the inverse cube transformation of error component
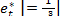
of multiplicative time series model. The probability density function (pdf) of the inverse cube root transformation of the multiplicative time series model was established, Further the
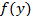
was mathematically proved as a proper pdf since
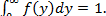
The Statistical properties (mean and variance) of the inverse cube transformation were equally shown.
-
Towards Efficiency in the Residual and Parametric Bootstrap Techniques
Acha Chigozie K.,
Omekara Chukwuemeka O.
Issue:
Volume 5, Issue 5, September 2016
Pages:
285-289
Received:
20 July 2016
Accepted:
30 July 2016
Published:
17 August 2016
Abstract: There are many bootstrap methods that can be used for statistical analysis especially in econometrics, biometrics, Statistics, Sampling and so on. The sole aim of this paper is to ascertain the accuracy and efficiency of the estimates from the independent and identically distributed (iid) simple linear regression (SLR) model under a variety of assessment conditions using bootstrap techniques. Analysis was carried out using S-plus statistical package on hypothetical data sets from a normal distribution with different group proficiency levels to buttress the arguments in the paper. In the course of the analysis, 268,800 scenarios were replicated 1000 times. The result shows a significant difference between the performances of the bootstrap methods used, namely; residual and parametric bootstrap techniques. From the analysis, the largest bias and standard error were always associated with model HP311 while the smallest bias and standard error values were associated with models HR311. The exception was found in the group proficiency level 3- N (1, 0.25), when the sample sizes were 200, 1000 and 10000 instead of model HR311 producing the smallest bias and standard error, model RP311 did. The significantly better performance of the residual bootstrap indicates the possible use of this technique in assessment of comparative performance and the capability of yielding very accurate, consistent, faster and extra-ordinarily reliable statistical inference under several assessment conditions.
Abstract: There are many bootstrap methods that can be used for statistical analysis especially in econometrics, biometrics, Statistics, Sampling and so on. The sole aim of this paper is to ascertain the accuracy and efficiency of the estimates from the independent and identically distributed (iid) simple linear regression (SLR) model under a variety of asse...
Show More
-
Estimating Survivor Function Using Adjusted Product Limit Estimator in the Presence of Ties
Job Isaac Mukangai,
Leo Odiwuor Odongo
Issue:
Volume 5, Issue 5, September 2016
Pages:
290-296
Received:
21 July 2016
Accepted:
1 August 2016
Published:
21 August 2016
Abstract: We develop an adjusted Product Limit estimator for estimating survival probabilities in the presence of ties that incorporates censored individuals using the proportion of failing for uncensored individuals. We also develop a variance estimator of the adjusted Product Limit estimator for calculating confidence intervals. Simulation studies are carried out to assess the performance of the developed estimator in comparison to the performance of Kaplan-Meier and modified Kaplan-Meier estimators. Some simulation results are presented and one real data is used for illustration. The results indicate that the proposed estimator out performs the other estimators in estimating survival probabilities in presence of ties.
Abstract: We develop an adjusted Product Limit estimator for estimating survival probabilities in the presence of ties that incorporates censored individuals using the proportion of failing for uncensored individuals. We also develop a variance estimator of the adjusted Product Limit estimator for calculating confidence intervals. Simulation studies are carr...
Show More
-
Research on the Status of Beijing-Tianjin-Hebei Logistics Operating
Issue:
Volume 5, Issue 5, September 2016
Pages:
297-304
Received:
31 July 2016
Accepted:
9 August 2016
Published:
25 August 2016
Abstract: Beijing-Tianjin-Hebei logistics enterprises has taken place a huge change in the service market under the development direction of personalized, diversified for consumer demand. Fierce market competition forces logistics enterprises to expand and improve its service connotation and extension. After many years, Beijing-Tianjin-Hebei logistics enterprises in constantly enlarging service market, has brought opportunities to innovate business pattern and national development of the logistics industry policy by making full use of the Internet, service organization, service product, service market, service mode innovation, has begun to take shape and provided a good foundation for the development of logistics, from the initial provides a single logistics service to socialization, specialization, and then to comprehensive that the whole society of logistics service, Beijing-Tianjin-Hebei logistics enterprises play an important role in the development of the logistics industry.
Abstract: Beijing-Tianjin-Hebei logistics enterprises has taken place a huge change in the service market under the development direction of personalized, diversified for consumer demand. Fierce market competition forces logistics enterprises to expand and improve its service connotation and extension. After many years, Beijing-Tianjin-Hebei logistics enterp...
Show More
-
Some Properties of the Size-Biased Janardan Distribution
Shakila Bashir,
Mujahid Rasul
Issue:
Volume 5, Issue 5, September 2016
Pages:
305-310
Received:
3 July 2016
Accepted:
19 July 2016
Published:
21 September 2016
Abstract: Janardan Distribution is one of the important distributions from lifetime models and it has many applications in real life data. A size-biased form of the two parameter Janardan distribution has been introduced in this paper, of which the size-biased Lindley distribution is a special case. Its moments, median, skewness, kurtosis and Fisher index of dispersion are derived and compared with the size-biased Lindley distribution. The shape of the size-biased Janardan distribution is also discussed with graphs. The survival function and hazard rate of the size-biased Janardan distribution have been derived and it is concluded that the hazard rate of the distribution is monotonically increasing. The flexibility in the reliability measures of the size-biased Janardan distribution have been discussed by stochastic ordering. To estimate the parameters of the size-biased Janardan distribution maximum likelihood equations are developed.
Abstract: Janardan Distribution is one of the important distributions from lifetime models and it has many applications in real life data. A size-biased form of the two parameter Janardan distribution has been introduced in this paper, of which the size-biased Lindley distribution is a special case. Its moments, median, skewness, kurtosis and Fisher index of...
Show More
-
Investigating Nepal’s Gross Domestic Product from Tourism: Vector Error Correction Model Approach
Basanta Dhakal,
Azay Bikram Sthapit,
Shankar Prasad Khanal
Issue:
Volume 5, Issue 5, September 2016
Pages:
311-316
Received:
31 August 2016
Accepted:
9 September 2016
Published:
28 September 2016
Abstract: This study tries to examine long run and short run relationship of foreign exchange earnings from tourism and average expenditure of international tourists towards share of gross domestic product (GDP) of Nepalese tourism by using Vector Error Correction Model (VECM). A multivariate time series analysis has been applied from the period of 1991 to 2014 tourism data of Nepal. The results of Johansen test of co-integration indicates there is one co-integrated vector under 4 lags of length among the share of gross domestic product of Nepalese tourism, foreign exchange earnings from tourism and average expenditure of international tourist. The long run relationship based on vector error correction model has indicated that coefficient of GDP elasticity with respect to average expenditure per visitor is more elastic as compare to coefficient of GDP elasticity with respect to foreign exchange earnings from tourism. The results of Granger causality analysis have depicted that there exists bidirectional causal relationship between GDP and expenditure per visitor and unidirectional causal relationship exists between GDP and foreign exchange earnings from tourism.
Abstract: This study tries to examine long run and short run relationship of foreign exchange earnings from tourism and average expenditure of international tourists towards share of gross domestic product (GDP) of Nepalese tourism by using Vector Error Correction Model (VECM). A multivariate time series analysis has been applied from the period of 1991 to 2...
Show More
-
A Multiplicative Bias Corrected Nonparametric Estimator for a Finite Population Mean
Bonface Miya Malenje,
Winnie Onsongo Mokeira,
Romanus Odhiambo,
George Otieno Orwa
Issue:
Volume 5, Issue 5, September 2016
Pages:
317-325
Received:
28 September 2015
Accepted:
20 October 2015
Published:
28 September 2016
Abstract: Nonparametric regression has been widely exploited in survey sampling to construct estimators for the finite population mean and total. It offers greater flexibility with regard to model specification and is therefore applicable to a wide range of problems. A major drawback of estimators constructed under this framework is that they are generally biased due to the boundary problem and therefore require modification at the boundary points. In this study, a bias robust estimator for the finite population mean based on the multiplicative bias reduction technique is proposed. A simulation study is performed to develop the properties of this estimator as well as assess its performance relative to other existing estimators. The asymptotic properties and coverage rates of our proposed estimator are better than those exhibited by the Nadaraya Watson estimator and the ratio estimator.
Abstract: Nonparametric regression has been widely exploited in survey sampling to construct estimators for the finite population mean and total. It offers greater flexibility with regard to model specification and is therefore applicable to a wide range of problems. A major drawback of estimators constructed under this framework is that they are generally b...
Show More
-
Poisson Inverse Gaussian (PIG) Model for Infectious Disease Count Data
Vincent Moshi Ouma,
Samuel Musili Mwalili,
Anthony Wanjoya Kiberia
Issue:
Volume 5, Issue 5, September 2016
Pages:
326-333
Received:
9 September 2016
Accepted:
21 September 2016
Published:
10 October 2016
Abstract: Traditionally, statistical models provide a general basis for analysis of infectious disease count data with its unique characteristics such as low disease counts, underreporting, reporting delays, seasonality, past outbreaks and lack of a number of susceptible. Through this approach, statistical models have provided a popular means of estimating safety performance of various health elements. Predictions relating to infectious disease outbreaks by use of statistical models have been based on Poisson modeling framework and Negative Binomial (NB) modeling framework in the case of overdispersion within the count data. Recent studies have proved that the Poisson- Inverse Gaussian (PIG) model can be used to analyze count data that is highly overdispersed which cannot be effectively analyzed by the traditional Negative Binomial model. A PIG model with fixed/varying dispersion parameters is fitted to two infectious disease datasets and its performance in terms of goodness-of-fit and future outbreak predictions of infectious disease is compared to that of the traditional NB model.
Abstract: Traditionally, statistical models provide a general basis for analysis of infectious disease count data with its unique characteristics such as low disease counts, underreporting, reporting delays, seasonality, past outbreaks and lack of a number of susceptible. Through this approach, statistical models have provided a popular means of estimating s...
Show More
